

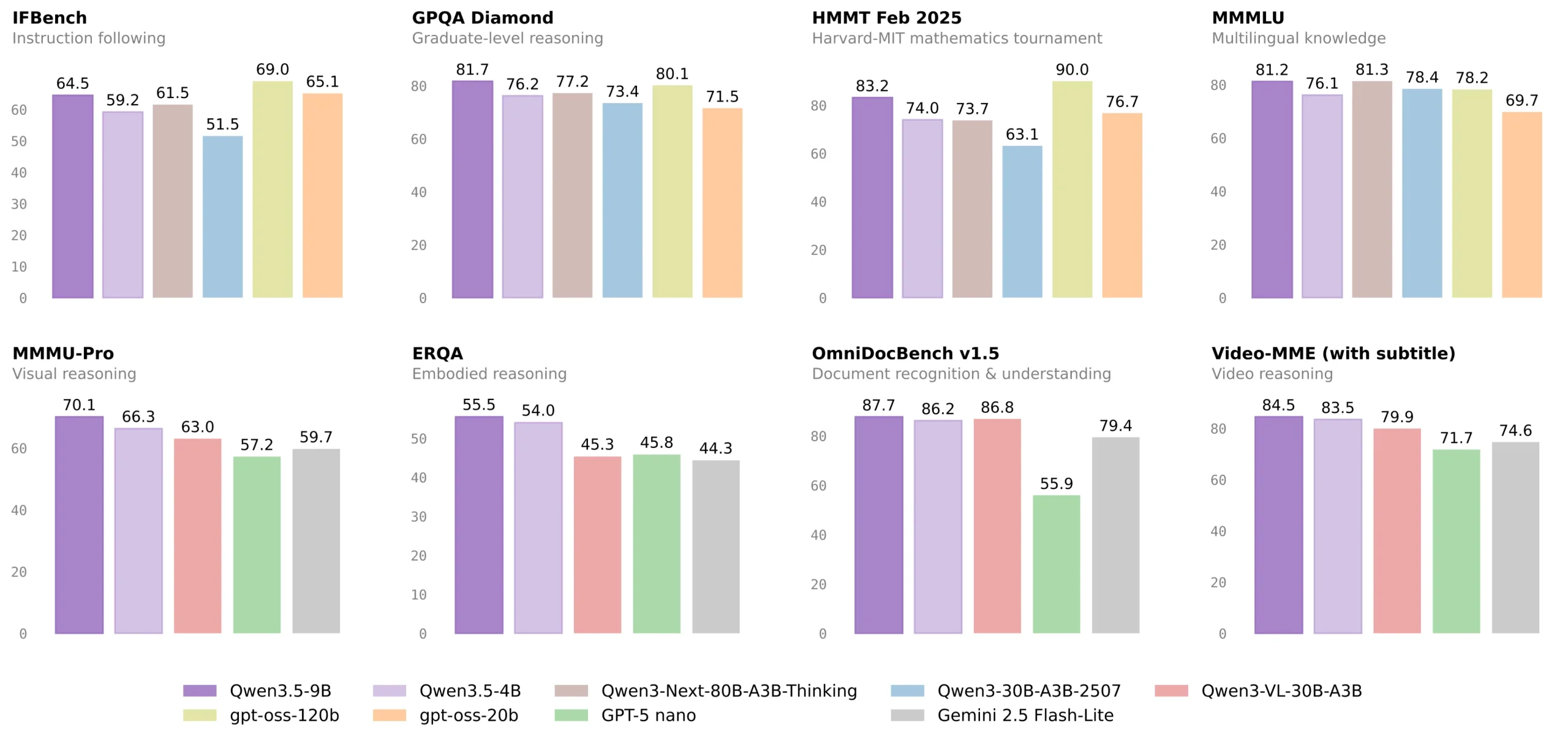
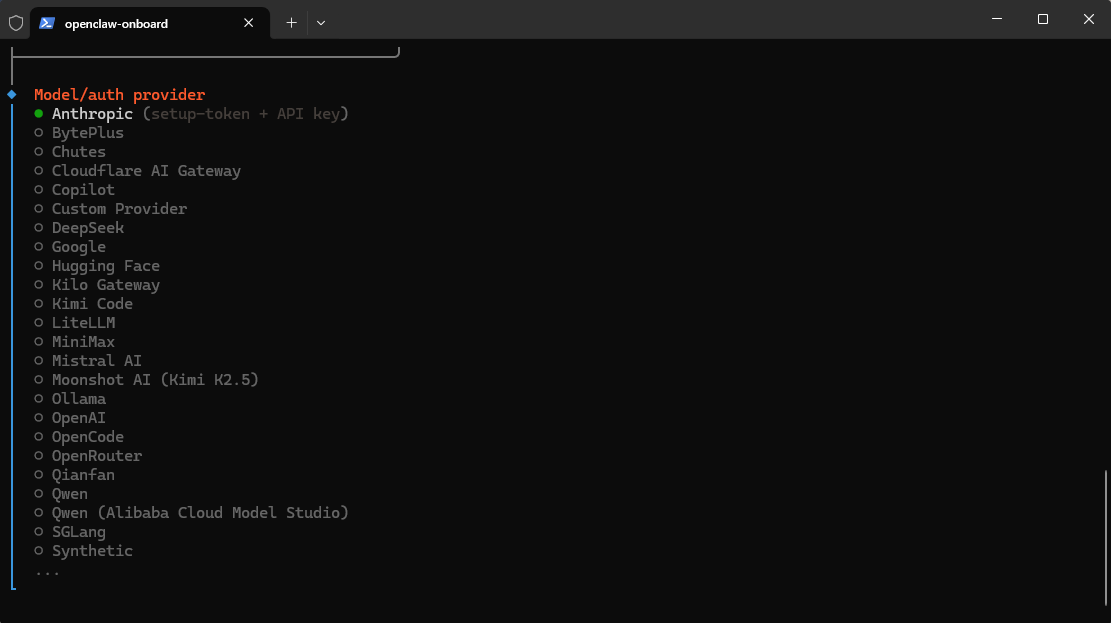
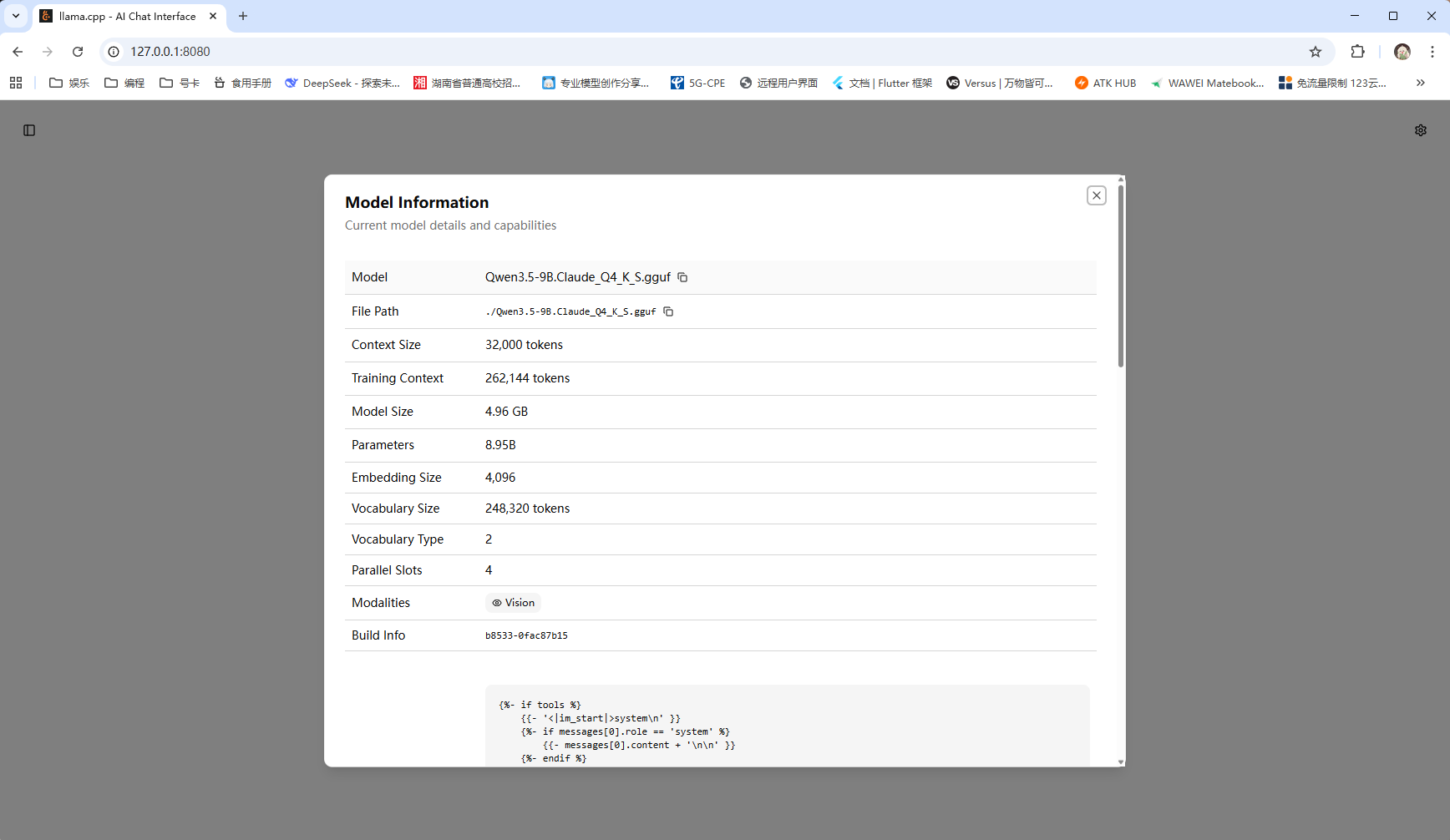
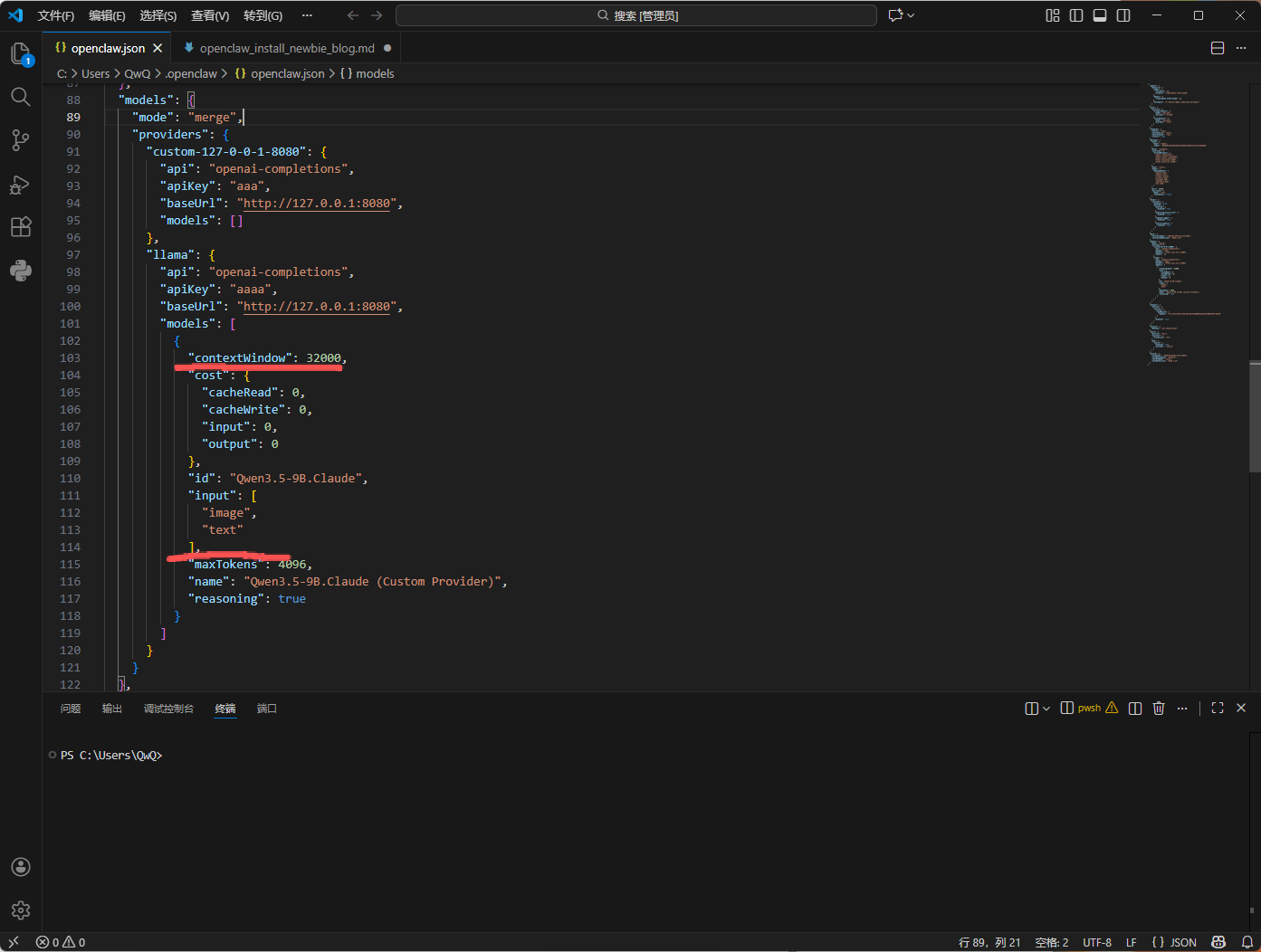
最近在折腾本地大模型,最终锁定了 Qwen3.5-9B.Claude_Q4_K_S.gguf。选它的理由很简单:风格对标 Claude 4.6 Opus,能有效规避那些让人头秃的冗余自我反思,加上千问本身的底子有目共睹,性能表现相当能打。
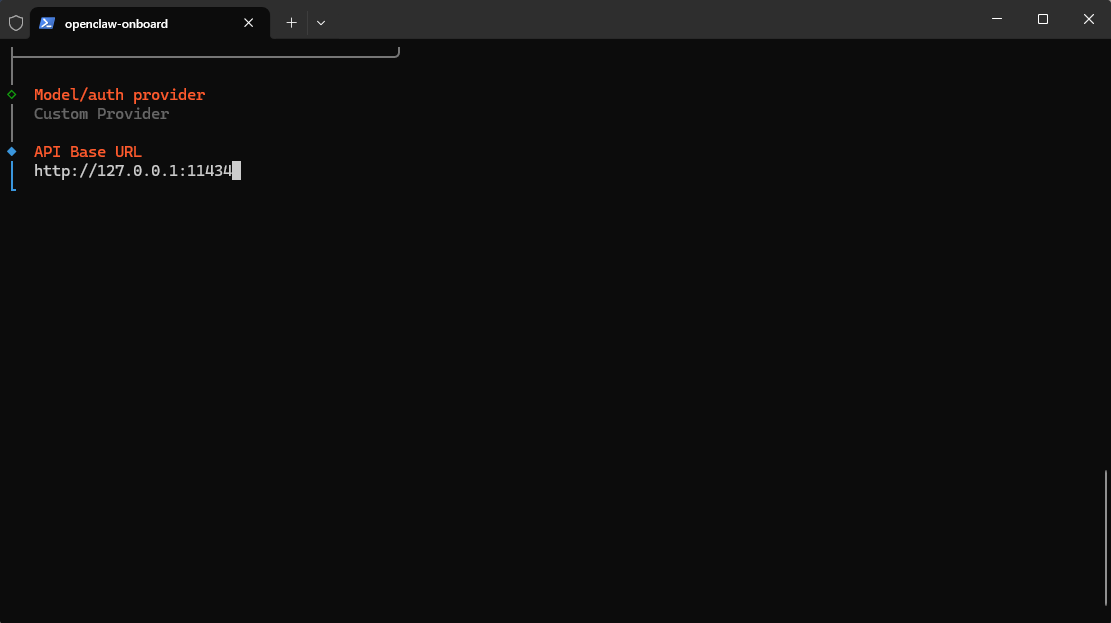
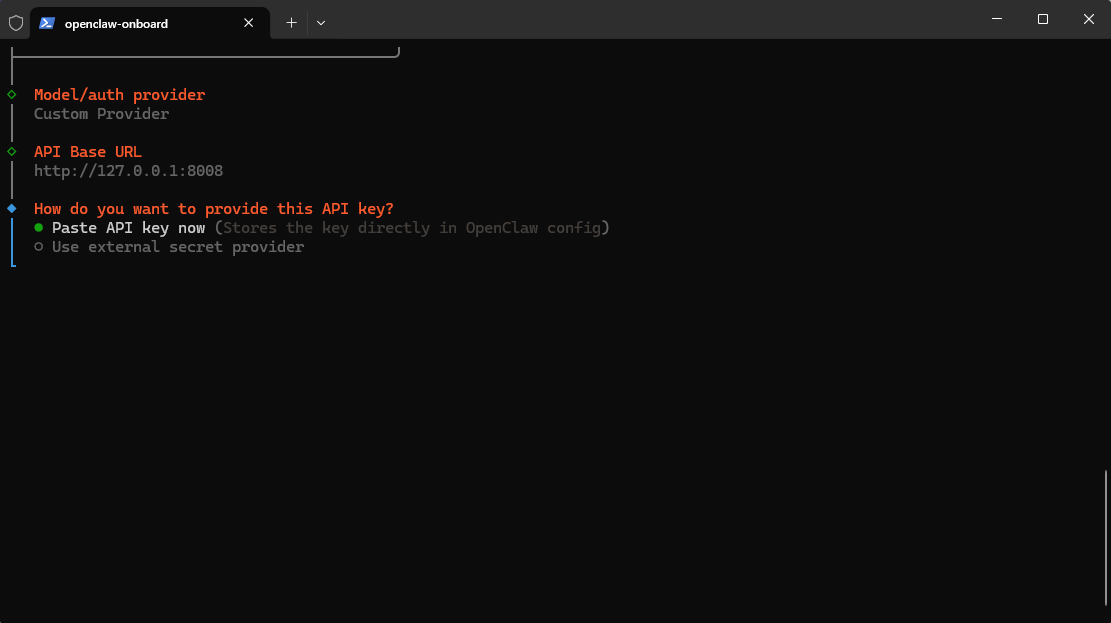
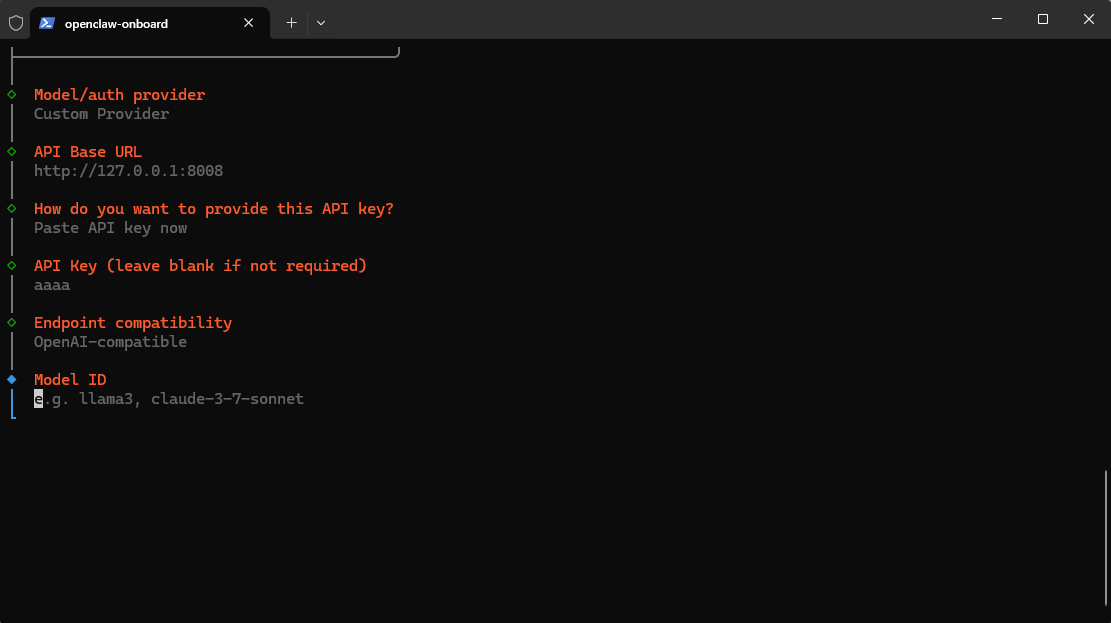
部署环境选用了 llama.cpp,以下是具体的启动脚本和参数解析。
启动脚本
@echo off
llama-server.exe -m ./Qwen3.5-9B.Claude_Q4_K_S.gguf --mmproj ./mmproj-F16-9b.gguf --reasoning on --flash-attn on --n-gpu-layers 16 -t 7 -b 512 --repeat-penalty 1.20 --repeat-last-n 256 --temp 0.7 --port 8080 --host 127.0.0.1 --fit on --ctx-size 32000 --cache-type-k q4_0 --cache-type-v q4_0 --cont-batching --defrag-thold 0.2 --mlock --mmap
pause
参数解读:
| 参数类别 | 关键参数 | 配置意图与说明 |
|---|---|---|
| 基础配置 | --port 8080 | 服务监听端口 |
--host 127.0.0.1 | 本地访问(外网需改为 0.0.0.0) | |
--ctx-size 32000 | 支持超长上下文窗口,处理长文本利器 | |
| 推理生成 | --temp 0.7 | 采样温度,平衡了创造性和稳定性 |
--repeat-penalty 1.20 | >1.0 抑制重复 token,让输出更丰富 | |
--reasoning on | 启用推理增强(支持 CoT 链式逻辑) | |
| 硬件加速 | --n-gpu-layers 16 | 卸载 16 层至 GPU(12G 显存可全卸载) |
--flash-attn on | 启用 Flash Attention 2,大幅提升速度 | |
-t 7 | CPU 线程数(建议 ≤ 物理核心数) | |
| 内存管理 | --cache-type-k/v q4_0 | KV 缓存 4-bit 量化,显著降低显存占用 |
--mlock | 锁定内存页,防止被系统交换,提升稳性 |
评论(0)
暂无评论